Project Ekler — Morphological Parser for Turkish Verbs
A morphological parser for Turkish verbs developed as part of a computational linguistics course. The parser analyzes the structure of Turkish verb forms and decomposes them into their constituent morphemes, handling the complex morphology of Turkish verbs.
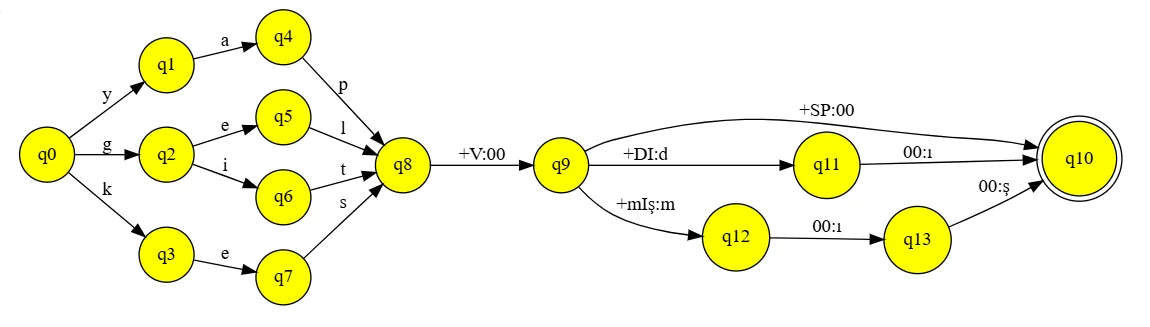
Overview
Turkish is an agglutinative language, meaning that it stacks affixes to the root of words to express grammatical relationships. These affixes come in a specific order, and typically also change due to vowel harmony in Turkish and depending on the sounds that they are attached to. This makes it difficult for non-native speakers to figure out the structure of Turkish words, especially those of verbs.
Project Ekler is a tool we've developed as a team in a computational linguistics class, to tackle this particular problem. It uses finite-state transducers to take a verb input from the user, parse its root and affixes to check whether its structure is correct, then reconstructs and returns the correct verb form.
If the user inputs an incorrect verb like yapdımış (incorrect form of yapmıştı meaning "he/she had done"), the tool:
- parses the verb structure:
yap + dı + mış - produces the verb in the correct ordering:
yap + mış + dı - applies phonological rules (devoicing in this case):
yap + mış + tı - returns the correct verb form:
yapmıştı
Reflections
This project was a great opportunity because it allowed us to apply theory to practice, design and implement a solution to a real-world problem as a team within time constraints. We were also newly introduced to Python in this class, which contributed to my interest in programming.
Looking back, I see several areas of improvement in our project. If I were to work on it again, my immediate next steps would be:
- Refactor the code to be more modular and easier to read.
- Refine our transducer architecture to handle edge cases, irregular and complex forms, and ambiguous inputs more reliably.
- Expand the scope of the tool to cover other parts of speech like nouns and adjectives.
- Add tests to ensure the accuracy of the parser and to catch any bugs.
- Revive the Streamlit app we built for the project, which is currently not working due to changes in Streamlit's API since then.
Further Reading
If you're interested in learning more about the project, computational linguistics, or NLP in general, check out the following resources:
- Project Ekler GitHub repo
- Quick introductions to finite state automata and finite state transducers by GeeksforGeeks
- Docs for HFST Python API, the library that we used for our transducers
- Jupyter notebooks for the Computational Morphology with HFST course by Helsinki University, available as a GitHub repo
- Jurafsky and Martin's NLP textbook, Speech and Language Processing